Table of Contents
Introduction
Recently I had to solve an issue that involved exporting a spreadsheet for a specific client. For some unknown reason, the spreadsheet export didn’t work as expected. After some days of serious code and console.log() investigations (among other debugging techniques), I found out the server was receiving signals to kill (SIGTERM) when executing the export spreadsheet job.
After some more investigation, I found out that the data of that specific company was too large to keep in memory at once - which was an issue for the way that it was being implemented.
Some things needed to change in order to make it work. What if there is a way of fetching smaller chunks of data, process the chunk, incrementally build the spreadsheet and incrementally upload them? Turns out Node.js Streams is a perfect use case for that.
What is a Stream?
First, let’s use the via negativa: what’s like when we don’t use stream? We wait for all the content is ready, then load it all to the memory:
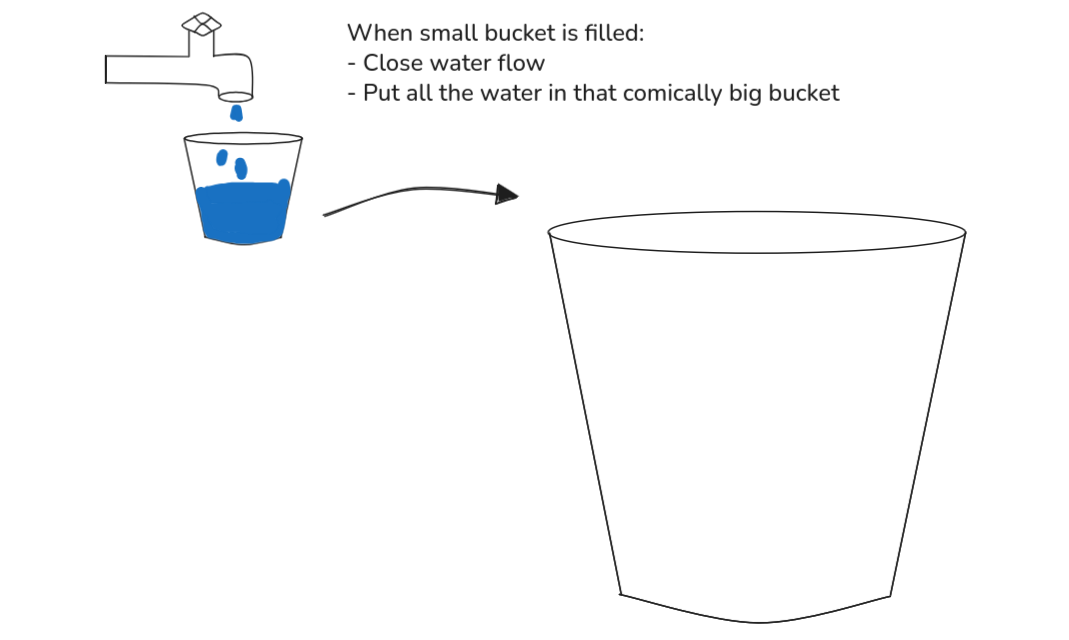
As for stream we can think of a constant flow of data. For example - in simpler and non-technical ways -, a constant flow of water. Behold my drawing:
And of course, you definitely already heard of streaming platforms: what does it mean when we watch a movie or listen to a song from a streaming platform? YouTube, for example, doesn’t need to send you the full video for you to watch - if that was the case, people would probably stop binge watching because boredom would likely send them away -. The server gradually sends data and the client asks and loads them dynamically.
In short, streams enables us to work with parts of data (chunk) as soon as they arrive, with no need for the data to be available all at once.
Understanding Node.js Streams
Node.js comes with four different types of Streams:
- Readable: Read data chunk by chunk as it arrives.
- Writable: Write data chunk by chunk, sending it out gradually.
- Duplex: Can both read and write data, working bidirectionally.
- Transform: Modify or transform the data as it passes through; it is a Duplex.
Let’s try a simple example before going further: Let’s create 100000 users and display them.
The Readable will be the source of the data:
import { Readable } from 'node:stream';
const readableStream = new Readable({
read: function () {
for (let i = 0; i <= 1e5 /* 100000 */; i++) {
const user = {
id: Date.now() + i,
name: `User-${i}`,
};
this.push(JSON.stringify(user));
}
this.push(null); // signaling the end of stream
},
});In the code above we:
- Created the readable stream with
Readable - Passed the
readfunction - Pushed the user data to the Readable
- Ended the stream by pushing
null
Then we can just console.log the data with a Writable:
import { Writable } from 'node:stream';
const writableStream = new Writable({
write(chunk, enconding, cb) {
console.log('User data:', chunk);
cb();
},
});In the code above we used Writable’s write function to:
- receive chunk data
- console.log chunk data
Then we can execute the pipeline:
import { Readable, Writable } from 'node:stream';
import { pipeline } from 'node:stream/promises';
const readableStream = new Readable({
read: function () {
for (let i = 0; i <= 1e5 /* 100000 */; i++) {
const user = {
id: Date.now() + i,
name: `User-${i}`,
};
this.push(JSON.stringify(user));
}
this.push(null); // signaling the end of stream
},
});
const writableStream = new Writable({
write(chunk, enconding, cb) {
console.log('User data:', chunk);
cb();
},
});
await pipeline(readableStream, writableStream);Voilá! Your terminal should get a bit laggy (I recommend maybe trying less than 1e5 times), but it just works!
But what if you want to read data (of JSON, like the current example) and write it in a file (.csv for example)? In that case, we’ll need a duplex, which is both a Readable and a Writable, but with a little difference: we’ll transform the data; so we’ll use a specific kind of duplex: a Transformer.
import { Readable, Transform } from 'node:stream';
import { pipeline } from 'node:stream/promises';
import { createWriteStream } from 'node:fs';
/* Same readable as before... */
const transformToCsv = new Transform({
transform: function (chunk, encoding, cb) {
const data = JSON.parse(chunk);
const dataToCsvLine = `${data.id},${data.name}\n`;
cb(null, dataToCsvLine);
},
});
await pipeline(readableStream, transformToCsv, createWriteStream('users.csv'));The flow here is simple, we receive the chunk in JSON format, transform it to csv format and let createWriteStream deal with the rest.
But if you execute it, you might realize there’s no header. Well… how to fix it? With streams as well! Let’s create a setHeader Transform that adds the header before the first execution:
const setHeader = (() => {
let headerSent = false;
return new Transform({
transform(chunk, encoding, cb) {
if (headerSent) {
return cb(null, chunk);
}
headerSent = true;
cb(null, 'id,name\n'.concat(chunk));
},
});
})();
await pipeline(
readableStream,
transformToCsv,
setHeader,
createWriteStream('users.csv'),
);How I actually fixed the issue
The fundamental things that needed to change were:
- how the data was being fetched
- how a spreadsheet was being built
- how the upload to S3 was being done
Building the spreadsheet as data arrives
The data was begin fetched from a MongoDB (with mongoose as the ODM) batch operation. It was fetching a lot of dat and sending to the worksheet once the data fetching was done. So, instead of fetching it all and assigning to a local variable, we used mongoose’s cursor(), in which we could actually use the .pipe() method and pass a Transformer that would build the data accordingly for the spreadsheet (like assigning correct and localized names for the columns). Now let’s understand how the spreadsheet building changed.
As for spreadsheet building, we were using xlsx lib, which is not bad per se, but it did not have any support for Node.js Streams (actually, it had, but only for the other way around - sheet to json) and exceljs was great for that since it offered streaming i/o by default.
For uploading… Well, S3 already accepts the body as a Readable.
Now that we know everything we need, let me actually show you the code.
Since we needed to generate different workbooks and we’ll use the xlsx stream in those different fetching functions, let’s create a function that creates the stream, adds the sheet (workbook) and finalizes the building operation:
import { PassThrough, type Readable } from 'stream';
import { Workbook } from 'exceljs';
export const createXlsxStream = () => {
const workbook = new Workbook();
// In here we use PassThrough which is a trivial
// implementation of a Transform stream that
// simply passes the input bytes across to the output.
const outputStream = new PassThrough();
let sheetsAdded = 0;
let finalized = false;
const addSheet = async ({
name,
dataStream,
}: {
name: string;
dataStream: Readable;
}) => {
if (finalized) throw new Error('XLSX stream already finalized');
const worksheet = workbook.addWorksheet(name);
let headersWritten = false;
return new Promise<void>((resolve, reject) => {
dataStream
.on('data', (row) => {
if (!headersWritten) {
// In here, we consider that the keys
// from the object are the headers
worksheet.addRow(Object.keys(row));
headersWritten = true;
}
worksheet.addRow(Object.values(row));
})
.on('end', () => {
sheetsAdded++;
resolve();
})
.on('error', reject);
});
};
const finalize = async () => {
if (finalized) return;
finalized = true;
if (sheetsAdded === 0) {
workbook.addWorksheet('Empty');
}
await workbook.xlsx.write(outputStream);
outputStream.end();
};
return {
stream: outputStream,
addSheet,
finalize,
};
};Adapt the upload helper function to allow stream:
import { type Readable } from 'stream';
import type { ManagedUpload } from 'aws-sdk/clients/s3';
import { Upload } from './Upload'; // s3 helper that just throws if there's error
type UploadStreamParams = {
stream: Readable;
uniqueId: string;
fileNameToDownload: string;
extension?: string;
};
export const uploadStream = async ({
stream,
uniqueId,
fileNameToDownload,
extension = 'xlsx',
}: UploadStreamParams): Promise<ManagedUpload.SendData | { error: Error }> => {
const uploadParams = {
Bucket: process.env.BUCKET_MEDIA,
Key: getKey(),
Body: stream,
ContentType:
'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet',
ContentDisposition: `attachment; filename="${fileNameToDownload}"`,
};
try {
return await Upload(uploadParams);
} catch (err) {
return { error: (err as any) };
}
};Using mongoose cursor piping
Mongoose cursors are really useful for fetching huge amounts of data because after we have a query that should return many documents we can use .cursor(). to:
- return a Readable that fetches documents from MongoDB in batches
pipe()it to connect it to writable/transform- if stream is busy, it signals the cursor to pause (handling backpressure)
As for our spreadsheet generation, let’s say we have a model that fetches a lot of Sales:
export const getSalesFromUserStream = async (
context: KoaAuthenticatedContext,
) => {
const cursor = Sales.find({
user: context.userId
removedAt: null,
}).cursor();
const transformStream = new Transform({
objectMode: true,
async transform(score, encoding, callback) {
try {
// this is the function that processes the information
// like dealing with i18n, column names, etc...
const row = await getSalesRow(score, context);
if (row) {
this.push(row);
}
callback();
} catch (error) {
callback(error);
}
},
});
cursor.on('error', (err) => transformStream.destroy(err));
return cursor.pipe(transformStream);
};Full flow of how a xlsx export would work
Now we finally have all the functions needed for the full process to work:
import { createXlsxStream } from './createXlsxStream.ts';
import { uploadStream } from './uploadStream.ts';
import { generateFileName } from './utils/createXlsxStream.ts';
import { getSalesFromUserStream } from './getSalesFromUserStream.ts';
// You can have more here..
const exportHugeSpreadsheet = async () => {
const { stream: xlsxStream, addSheet, finalize } = createXlsxStream();
const filename = `performance-review-${review.title}.xlsx`;
const { uniqueId, fileNameToDownload } = generateFileName(filename);
const uploadPromise = uploadStream({
stream: xlsxStream,
uniqueId,
fileNameToDownload,
extension: 'xlsx',
});
await addSheet({
name: 'Sales',
dataStream: await getSalesFromUserStream(
context,
),
});
// You can add more sheets...
// Finalize xlsx build
await finalize();
// Wait for upload to complete
const uploadResult = await uploadPromise;
if (uploadResult?.error) {
throw new Error('upload failed');
}
// Done!
// Maybe notify your users or send a response? Your call.
await notifyUserExportIsDone();
}
References
- Node.js documentation
- Erick Wendel About NodeJS Streams (introductory content, useful for portuguese speaking people that need visual and hands-on content to learn)
- Erick Wendel talk - Deep dive into Node.js Streams
Conclusion
I hope you could get the grasp of how Node.js Streams can be helpful, but mostly, I hope you could understand how it can leverage operations in real world projects.
If you have any doubts, questions or you just want to chat, feel free to get in touch.